|
"Perhaps you've noticed the new Microsoft Office formats" is something you'd say back in 2007. Nevertheless, I'd bet that a good portion of people haven't looked into what that new "x" is at the end of all default files (.docx, .xlsx, .pptx) and an equal number of people probably don't care. However, I'd like to try and convince these doubters just how great this is! This "x" stands for XML (extensible markup language) and makes the file formats seem hipper than their x-less counterparts. Rather than documents and spreadsheets being stored as binary files, which are difficult to read, all information is stored in easily read zipped-xml files. That's right - all .abcx files are just zip files.
Let's look at an example Excel file (Ex-Book.xlsx):

It has a little bit of everything: values, text, color formats, comments, and formulas. If we wish to look at how the data are stored, we can easily change the extension of the file from .xlsx to .zip.

Naturally, we already have a way to take care of zip files in Stata with the command unzipfile. So from this point on, we're going to navigate this file strictly using Stata. My Excel workbook is located on my desktop, so let's unzip it.
cap mkdir unzipbook cd unzipbook unzipfile ../Ex-Book.xlsx, replace dir xl/ 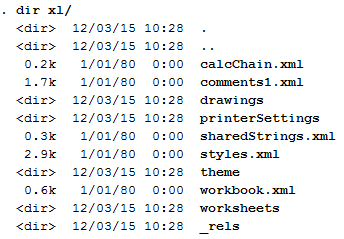
Note that we didn't have to change the extension, and we now have a list of files and directories under the "xl" folder. Files and properties of interest:
These are good reference files, but our main interest is located within the "worksheets" directory under our "xl" folder. Here, we can find each sheet named sheet1, sheet2, sheet3, etc. The sheets are indexed according to the workbook.xml files (ex: "rId1" corresponds to sheet1). I've always had trouble getting formulas out of Excel. Instead of resorting to VBA, we can now use Stata to catalog this information (I've found this very useful for auditing purpose). Here's a snippet of our worksheets/sheet1.xml file: 
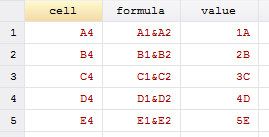
Interpreting this section, we can see that it contains rows 2-4 which corresponds to our strings (A, B, C), our styles (Red, Orange, Yellow), and our formulas. Going from top to bottom, by deduction we can see that our first <c> or cell class contains a value of 3 and references cell D2 with the style of 7. Here, since the type is a string ("s"), we need to reference our sharedStrings.xml file to see what the fourth string is. We look for the fourth string, since the count initializes at zero rather than looking at the third string. Our fourth observation is a "D" and our fifth observation is an "E" in the shareStrings.xml file.
The third row contains our colored cells without any data. Therefore, they have no values, but contain styles corresponding to the fill colors. A quick note: the order here goes (3, 4, 2, 5, 6) because I accidentally chose yellow first. Finally, the most valuable part of this exercise (for me at least) are the formulas. Cell A4 contains the formula "=A1&A2" and displays the evaluated value of the formula. When linking to other workbooks, the workbook path will likely be another reference such as [1], [2], [3], etc. A quick use of some nice Stata commands below yields a simple code for creating an index of your workbook's information.
tempfile f1 f2
filefilter xl/worksheets/sheet1.xml `f1', from("<c") to("\r\n<c")
filefilter `f1' `f2', from("</c>") to("</c>\r\n")
import delimited `f2', delimit("@@@", asstring) clear
keep if regexm(v1, "([^<>]+)")
gen value = regexs(1) if regexm(v1, "v>([^<>]+)")
replace formula = subinstr(formula, "&", "&", .)
keep cell formula value
Thanks to that little x, we are able to easily obtain meta-information about our Excel files, presentations, or even Word documents. Think about having to look through thousands of documents to find a specific comment or reference - seems like a simple loop would suffice. Maybe that x is pretty cool after all.
2 Comments
5/6/2022 07:32:19 am
ks for sharing the article, and more importantly, your personal experience mindfully using our emotions as data about our inner state and knowing when it’s better to de-escalate by taking a time out are great tools. Appreciate you reading and sharing your story since I can certainly relate and I think others can to ks for sharing the article, and more importantly, your personal experiescnce mindfully using oscur emotions as data about our inner state and knowing when it’s better to de-escalate by taking a time out are great tools. Appreciate you reading and sharing your story since I can certainly relate and I think others can to Leave a Reply. |
AuthorWill Matsuoka is the creator of W=M/Stata - he likes creativity and simplicity, taking pictures of food, competition, and anything that can be analyzed. Archives
July 2016
Categories
All
|
||
 RSS Feed
RSS Feed